Μια περίληψη των βασικών καινοτομιών στην γενετική ΤΝ (Generative AI), βασισμένη στον Hype Cycle της Gartner
Τα τελευταία χρόνια η ΤΝ έχει μπει για τα καλά στη ζωή μας, ορμώμενη κυρίως από την Γενετική ΤΝ (Generative AI), η οποία έγινε ευρέως γνωστή στο πλατύ κοινό το τελευταίο διάστημα, μέσω πρωτοβουλιών, προϊόντων και υπηρεσιών από διάφορους τεχνολογικούς κολοσσούς. Η δημοφιλία της έχει να κάνει και με τα ακόλουθα :
- Ο όρος «AI» χρησιμοποιείται συχνά ευρέως, περιλαμβάνοντας τα πάντα, από τη βασική μηχανική μάθηση (ML) έως την τεχνητή γενική νοημοσύνη (AGI). Όταν εφαρμόζεται στα περισσότερα έργα ML, το παρατραβάει, υπονοώντας ικανότητες ανθρώπινου επιπέδου που δεν είναι πάντα ακριβείς.
- Εργαλεία όπως το ChatGPT (και τα υπόλοιπα από άλλους κατασκευαστές), τα οποία παράγουν κείμενο, εικόνες ή άλλο περιεχόμενο, έχουν τροφοδοτήσει τον ενθουσιασμό. Η ικανότητά τους να δημιουργούν ρεαλιστικά αποτελέσματα είναι εντυπωσιακή, αλλά εξακολουθούν να είναι εξειδικευμένα μοντέλα, όχι AGI.
- Ενώ η Γενετική ΤΝ έχει υπερτιμηθεί βραχυπρόθεσμα, οι μακροπρόθεσμες δυνατότητές της είναι υποτιμημένες. Μπορεί να ενισχύσει τη δημιουργικότητα, να αυτοματοποιήσει εργασίες και να βελτιώσει τη λήψη αποφάσεων
Συνοπτικά, η εισβολή της Γενετικής ΤΝ μπορεί να αποσπάσει την προσοχή από τις πρακτικές εφαρμογές ML. Είναι σημαντικό να γίνεται διάκριση μεταξύ των ερευνητικών επιτευγμάτων και των πραγματικών επιχειρηματικών λύσεων.
Έχοντας τα παραπάνω υπόψη, ας προχωρήσουμε να δούμε πως διαμορφώνεται (μέχρι στιγμής) η πορεία της.
![]()
![]()
![]()
![]()
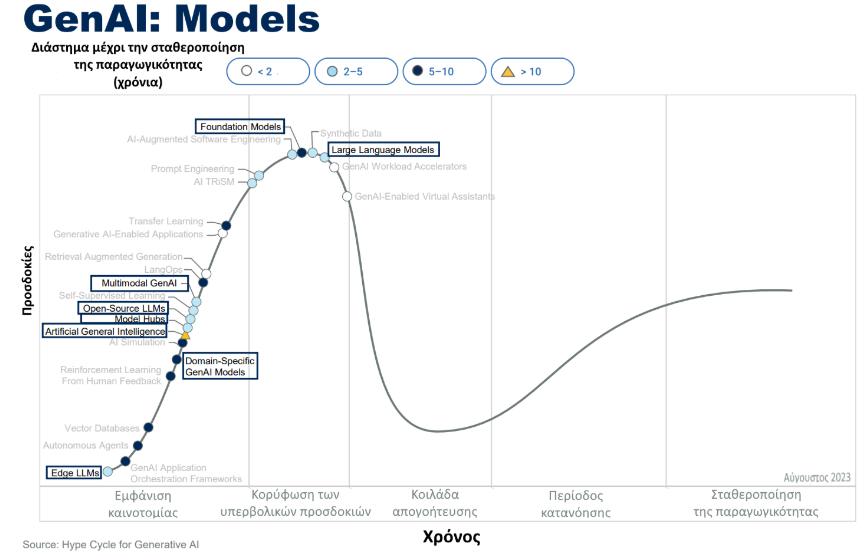
Όπως παρατηρούμε, υπάρχει πληθώρα μοντέλων, υποδομών και τεχνικών, που θα επιτρέψουν την πρόοδο και θα την χρησιμοποιήσουν για την παραγωγή εφαρμογών και βέλτιστων τεχνικών.
Ας δούμε λοιπόν την ανάλυση :
![]()
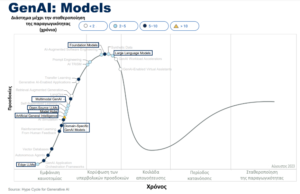
Ο σκοπός των μοντέλων στη γεννητική ΤΝ είναι να δημιουργούν νέο περιεχόμενο -είτε πρόκειται για κείμενο, είτε για εικόνες, είτε για άλλες μορφές- με βάση τα πρότυπα που προκύπτουν από τα υπάρχοντα δεδομένα. Αυτά τα μοντέλα μαθαίνουν αναπαραστάσεις που συλλαμβάνουν τα θεμελιώδη χαρακτηριστικά των δεδομένων εισόδου, επιτρέποντάς τους να παράγουν νέα και συνεκτικά αποτελέσματα
- Foundation or Large AI models : (Θεμελιώδη Μοντέλα)Είναι μοντέλα που εκπαιδεύονται σε μια ευρεία γκάμα συνόλων δεδομένων με αυτοεποπτευόμενο τρόπο. Τα θεμελιώδη μοντέλα είναι τεχνολογίες γενικής χρήσης που μπορούν να υποστηρίξουν ένα ευρύ φάσμα χρήσεων. Η δημιουργία θεμελιωδών μοντέλων είναι συχνά ιδιαίτερα απαιτητική σε πόρους, με τα πιο ακριβά μοντέλα να κοστίζουν εκατοντάδες εκατομμύρια δολάρια για να χρησιμοποιηθούν τα υποκείμενα δεδομένα και οι υπολογισμοί που απαιτούνται. Σε αντίθεση με τα παραδοσιακά μοντέλα ML, τα οποία εξειδικεύονται σε συγκεκριμένες εργασίες, τα FM είναι γενικής χρήσης και ευέλικτα. Μπορούν να χρησιμεύσουν ως σημείο εκκίνησης για την ανάπτυξη μοντέλων ML και εφαρμογών πιο γρήγορα και οικονομικά.
- Large Language Models (LLM) : Τα Μεγάλα Γλωσσικά Μοντέλα είναι ένας τύπος θεμελιωδών μοντέλων που εκπαιδεύονται σε τεράστιες ποσότητες δεδομένων, επιτρέποντάς τους να κατανοούν και να παράγουν φυσική γλώσσα και άλλους τύπους περιεχομένου. Έχουν σχεδιαστεί για να εκτελούν ένα ευρύ φάσμα εργασιών, όπως η παραγωγή συγκροτημένων και σχετικών με το πλαίσιο απαντήσεων, η μετάφραση γλωσσών, η σύνοψη κειμένου, η απάντηση σε ερωτήσεις, ακόμη και η υποβοήθηση σε εργασίες δημιουργικής γραφής ή δημιουργίας κώδικα. Καθώς συνεχίζουν να εξελίσσονται και να βελτιώνονται, τα LLM αναδιαμορφώνουν τον τρόπο με τον οποίο αλληλεπιδρούμε με την τεχνολογία και έχουμε πρόσβαση σε πληροφορίες. Είναι σημαντικό να σημειωθεί ότι ενώ είναι ισχυρά εργαλεία, κληρονομούν επίσης τις ανακρίβειες και προκαταλήψεις που υπάρχουν στα δεδομένα στα οποία εκπαιδεύονται. Ως εκ τούτου, είναι ζωτικής σημασίας να χρησιμοποιούνται με υπευθυνότητα και να έχουμε επίγνωση των περιορισμών τους.
- Domain specific AI models : Έχουν σχεδιαστεί για την αντιμετώπιση συγκεκριμένων προβλημάτων σε έναν καθορισμένο τομέα. Αυτά τα μοντέλα αξιοποιούν τεχνικές μηχανικής μάθησης για να μαθαίνουν μοτίβα και να κάνουν προβλέψεις με βάση τα δεδομένα στα οποία έχουν εκπαιδευτεί. Αυτό έχει ως αποτέλεσμα πιο ακριβείς και αξιόπιστα αποτελέσματα προσαρμοσμένα στις ανάγκες συγκεκριμένων βιομηχανιών ή εφαρμογών. Μερικοί τομείς στους οποίους υπάρχουν τέτοια μοντέλα είναι :
- Επεξεργασία φυσικής γλώσσας — Natural Language Processing (NLP)
- Μηχανική όραση — Computer Vision
- Συστήματα συστάσεων — Recommendation Systems
- Ιατρικά μοντέλα — Medical AI
- Χρηματοοικονομικά — Financial AI
- Open souce LLM’s : Μεγάλα γλωσσικά μοντέλα ανοιχτού κώδικα. Μερικά από τα πλεονεκτήματά τους περιλαμβάνουν:
- Διαφάνεια: Τα μοντέλα ανοικτού κώδικα επιτρέπουν στους χρήστες να επιθεωρούν τον κώδικα, την αρχιτεκτονική και τα δεδομένα εκπαίδευσης. Αυτή η διαφάνεια δημιουργεί εμπιστοσύνη.
- Προσαρμογή: Οι προγραμματιστές μπορούν να τελειοποιήσουν αυτά τα μοντέλα για συγκεκριμένες εργασίες, προσαρμόζοντάς τα στις ανάγκες τους.
- Αποτελεσματικότητα ως προς το κόστος:
- Δεν υπάρχουν τέλη αδειοδότησης: Οι οργανισμοί μπορούν να χρησιμοποιούν μοντέλα LLM ανοικτού κώδικα χωρίς πρόσθετο κόστος.
- Φιλικό προς τον προϋπολογισμό: Οι μικρότερες εταιρείες και οι ερευνητές επωφελούνται από τα ελεύθερα διαθέσιμα μοντέλα.
- Μειωμένη εξάρτηση από προμηθευτές:
- Ανεξαρτησία: Οι οργανισμοί δεν δεσμεύονται από συγκεκριμένο προμηθευτή ή από μια ιδιόκτητη λύση.
- Ευελιξία: Μπορούν να τροποποιούν και να επεκτείνουν τα μοντέλα ανοικτού κώδικα ανάλογα με τις ανάγκες.
- Συνεργασία με την κοινότητα:
- Τα έργα ανοικτού κώδικα ευδοκιμούν στη συνεργασία. Οι προγραμματιστές συνεισφέρουν βελτιώσεις, διορθώσεις σφαλμάτων και νέα χαρακτηριστικά.
- Συλλογική γνώση: Μια παγκόσμια κοινότητα εξασφαλίζει συνεχή υποστήριξη και βελτιώσεις.
- Μειονεκτήματα που σχετίζονται με αυτά (όμοια πολλές φορές με οτιδήποτε ανοιχτού κώδικα)
- Εκπαίδευση που απαιτεί σημαντικούς πόρους:
- Η εκπαίδευση μεγάλων LLM απαιτεί σημαντικούς υπολογιστικούς πόρους (όπως GPU ή TPU) και σημαντικό χρόνο.
- Μικρότεροι οργανισμοί ή άτομα μπορεί να δυσκολεύονται με αυτές τις απαιτήσεις.
- Πολυπλοκότητα και εξειδίκευση:
- Η εφαρμογή και η λεπτομερής ρύθμιση των LLM μπορεί να είναι πολύπλοκη. Οι προγραμματιστές χρειάζονται τεχνογνωσία στη μηχανική μάθηση, την επεξεργασία φυσικής γλώσσας και την αξιολόγηση μοντέλων.
- Η έλλειψη εξειδίκευσης μπορεί να οδηγήσει σε μη βέλτιστα αποτελέσματα.
- Συντήρηση και ενημερώσεις:
- Τα μοντέλα ανοικτού κώδικα χρειάζονται τακτική συντήρηση, διορθώσεις σφαλμάτων και ενημερώσεις.
- Η παρακολούθηση της τελευταίας έρευνας και η προσαρμογή των μοντέλων μπορεί να είναι πρόκληση.
- Μεροληπτικότητα και αμεροληψία:
- Τα LLM μαθαίνουν από υπάρχοντα δεδομένα, τα οποία ενδέχεται να περιέχουν προκαταλήψεις. Αυτές οι προκαταλήψεις διαδίδονται και στις απαντήσεις του μοντέλου.
- Η διασφάλιση της αντικειμενικότητας και ο μετριασμός των προκαταλήψεων είναι μια συνεχής πρόκληση.
- Επεκτασιμότητα και ανάπτυξη:
- Η ανάπτυξη σε κλίμακα (π.χ. για chatbots ή υποστήριξη πελατών) απαιτεί σχεδιασμό και βελτιστοποίηση της υποδομής.
- Η εξασφάλιση απαντήσεων χαμηλής καθυστέρησης για εφαρμογές πραγματικού χρόνου μπορεί να είναι δύσκολη.
- Έλλειψη εξειδίκευσης:
- Τα προ-εκπαιδευμένα LLM είναι μοντέλα γενικής χρήσης. Η λεπτομερής ρύθμιση για συγκεκριμένες εργασίες είναι απαραίτητη.
- Η προσαρμογή τους στις ανάγκες συγκεκριμένων τομέων είναι χρονοβόρα και κοστοβόρα.
- Edge LLM’s : Τα Μεγάλα γλωσσικά μοντέλα που «τρέχουν» τοπικά και όχι σε απομακρυσμένη κεντρική τοποθεσία.
Μερικά πλεονεκτήματά τους μπορεί να είναι :
- Ανταπόκριση σε πραγματικό χρόνο: Παρέχουν απρόσκοπτη εμπειρία χρήστη και γρήγορη λήψη αποφάσεων.
- Διασφάλιση απορρήτου: Η ανάπτυξη LLM στην ακμή διασφαλίζει ότι τα ευαίσθητα δεδομένα παραμένουν τοπικά, μειώνοντας τον κίνδυνο παραβίασης.
- Λειτουργικότητα εκτός σύνδεσης: Μπορούν να λειτουργήσουν ακόμη και χωρίς σταθερή σύνδεση στο διαδίκτυο.
- Εξατομίκευση: Μαθαίνουν μοτίβα ειδικά για τον χρήστη, ενισχύοντας την εξατομίκευση.
- Μειωμένη καθυστέρηση : Αυτό έχει σημαντική σημασία, ιδίως σε εφαρμογές όπως τα chatbots ή οι υπηρεσίες ζωντανής μετάφρασης που βασίζονται σε μεγάλο βαθμό σε απαντήσεις σε πραγματικό χρόνο.
Πιθανά μειονεκτήματα :
- Υψηλότερο αρχικό κόστος: Η εγκατάσταση τοπικών διακομιστών για την εκτέλεση μεγάλων γλωσσικών μοντέλων μπορεί να είναι δαπανηρή εάν δεν διαθέτετε υλικό και λογισμικό υψηλών προδιαγραφών.
- Πολυπλοκότητα: Η τοπική εκτέλεση μοντέλων LLM μπορεί να είναι δύσκολη, χρονοβόρα και να συνεπάγεται λειτουργικά έξοδα. Υπάρχουν πολλά κινούμενα μέρη και πρέπει να ρυθμίσετε και να συντηρήσετε τόσο το λογισμικό όσο και την υποδομή.
- Περιορισμένη επεκτασιμότητα: Δεν μπορείτε να αναβαθμίσετε ή να μειώσετε την κλίμακα ανάλογα με τη ζήτηση. Η εκτέλεση πολλαπλών LLM μπορεί να απαιτεί περισσότερη υπολογιστική ισχύ από αυτή που είναι εφικτή σε ένα μόνο μηχάνημα και μπορεί να είναι αναγκαία η «σμύκρινση» του μοντέλου.
- Διαθεσιμότητα: Οι τοπικοί διακομιστές είναι λιγότερο ανθεκτικοί. Σε περίπτωση βλαβών του συστήματος, η πρόσβαση στα LLM σας τίθεται σε κίνδυνο. Από την άλλη πλευρά, οι πλατφόρμες νέφους προσφέρουν πολλαπλά επίπεδα εφεδρείας και παρουσιάζουν μικρότερο χρόνο διακοπής λειτουργίας.
- Πρόσβαση σε προ-εκπαιδευμένα μοντέλα: Η πρόσβαση στα πιο σύγχρονα μοντέλα μεγάλων γλωσσών τελευταίας τεχνολογίας για λεπτομερή ρύθμιση και ανάπτυξη μπορεί να μην είναι άμεσα ή και καθόλου διαθέσιμη.
- Ασφάλεια: Οι συσκευές στην ακμή είναι ευάλωτες σε φυσικές επιθέσεις ή μη εξουσιοδοτημένη πρόσβαση και απαιτείται ισχυρή διαχείριση των πρωτοκόλλων ασφαλείας.
- Model Hubs : Οι κεντρικοί κόμβοι μοντέλων ΤΝ λειτουργούν ως κεντρικά αποθετήρια για προ-εκπαιδευμένα μοντέλα μηχανικής μάθησης. Χαρακτηριστικές ιδιότητες και πλεονεκτήματά/μειονεκτήματα:
- Συγκέντρωση μοντέλων: Ερευνητές και επαγγελματίες συνεισφέρουν τα προ-εκπαιδευμένα μοντέλα τους στον κόμβο. Τα μοντέλα αυτά καλύπτουν ένα ευρύ φάσμα εργασιών, όπως η επεξεργασία φυσικής γλώσσας (NLP), η όραση υπολογιστών και άλλα.
- 2. Έλεγχος εκδόσεων: Κάθε μοντέλο διαθέτει μια έκδοση, επιτρέποντας στους χρήστες να επιλέξουν το καταλληλότερο. Αυτό διασφαλίζει την δυνατότητα αναπαραγωγής και συμβατότητας.
- Πρόσβαση και χρήση:
- Λήψη: Οι χρήστες μπορούν να κατεβάζουν προ-εκπαιδευμένα μοντέλα απευθείας από τον κόμβο.
- Διαμόρφωση: Οι ερευνητές/χρήστες μπορούν να τελειοποιήσουν αυτά τα μοντέλα σε συγκεκριμένες εργασίες χρησιμοποιώντας τα δικά τους δεδομένα.
- Συμπεράσματα: Οι προγραμματιστές μπορούν να χρησιμοποιήσουν αυτά τα μοντέλα για προβλέψεις χωρίς εκπαίδευση από το μηδέν.
Κοινοτική συνεργασία:
- Συνεισφορές: Η κοινότητα συνεισφέρει κώδικα, τεκμηρίωση και βελτιώσεις.
- Ανατροφοδότηση: Οι χρήστες παρέχουν ανατροφοδότηση, αναφέρουν προβλήματα και προτείνουν βελτιώσεις.
- APIs και βιβλιοθήκες:
- Οι κόμβοι παρέχουν API ή βιβλιοθήκες (π.χ. πακέτα Python) για εύκολη ενσωμάτωση σε έργα.
- Οι χρήστες μπορούν να φορτώνουν μοντέλα, να κάνουν tokenize κειμένου και να εκτελούν εξαγωγή συμπερασμάτων χρησιμοποιώντας αυτά τα API.
- Πολύπλοκοτητα: Η πολυπλοκότητα της διαχείρισης και της ενσωμάτωσης διαφόρων προ-εκπαιδευμένων μοντέλων μπορεί να αποτελέσει πρόκληση, ιδίως για τους αρχάριους².
- Θέματα επαναληψιμότητας: Μπορεί να υπάρξουν δυσκολίες στην αναπαραγωγή των αποτελεσμάτων λόγω διαφορών στα περιβάλλοντα ή στα σύνολα δεδομένων.
- Ανησυχίες σχετικά με το απόρρητο των δεδομένων: Η κοινή χρήση δεδομένων και μοντέλων μπορεί να εγείρει ζητήματα προστασίας της ιδιωτικής ζωής, ιδίως αν πρόκειται για ευαίσθητες πληροφορίες.
- Κίνδυνοι κυβερνοασφάλειας: Καθώς τα συστήματα ΤΝ ενσωματώνονται όλο και περισσότερο σε διάφορους τομείς, μπορεί να γίνουν στόχοι κυβερνοεπιθέσεων.
- Έλλειψη ελέγχου: Οι χρήστες ενδέχεται να έχουν περιορισμένο έλεγχο των μοντέλων και των ενημερώσεών τους, γεγονός που μπορεί να επηρεάσει τη σταθερότητα και τις επιδόσεις.
- Multimodal AI: Η πολυτροπική γενετική ΤΝ αναφέρεται σε μοντέλα τεχνητής νοημοσύνης που μπορούν να επεξεργάζονται και να παράγουν περιεχόμενο σε πολλαπλούς τύπους δεδομένων, όπως κείμενο, εικόνες, ήχο και άλλα. Αυτό έρχεται σε αντίθεση με τη μονοτροπική ΤΝ, η οποία εξειδικεύεται σε έναν µόνο τύπο δεδοµένων. Η πολυτροπική τεχνητή νοημοσύνη στοχεύει να μιμηθεί την κατανόηση που μοιάζει με την ανθρώπινη, ενσωματώνοντας διάφορες αισθητηριακές εισροές για την ερμηνεία του κόσμου.Η ανάπτυξη της πολυτροπικής τεχνητής νοημοσύνης θεωρείται ως ένα σημαντικό βήμα προς πιο εξελιγμένα και ευέλικτα συστήματα τεχνητής νοημοσύνης που μπορούν να κατανοούν καλύτερα και να αλληλεπιδρούν με τον κόσμο με τρόπο παρόμοιο με την ανθρώπινη αντίληψη και νόηση. Τα μοντέλα αυτά είναι ιδιαίτερα υποσχόμενα για εφαρμογές που απαιτούν βαθιά κατανόηση του πλαισίου, όπως η δημιουργία περιεχομένου, η εκπαίδευση και τα αυτόνομα συστήματα. Χαρακτηριστικές ιδιότητες και πλεονεκτήματά/μειονεκτήματα
- Βελτιωμένη ακρίβεια: Μπορούν να επιτύχουν μεγαλύτερη ακρίβεια σε εργασίες όπως η αναγνώριση ομιλίας, η ανάλυση συναισθήματος και η αναγνώριση αντικειμένων, χρησιμοποιώντας τα συμπληρωματικά χαρακτηριστικά πολλών διαφορετικών μοντέλων.
- Φυσική αλληλεπίδραση: Επιτρέπουν εισροές από πολλές μορφές, συμπεριλαμβανομένης της ομιλίας, των χειρονομιών και των εκφράσεων του προσώπου, βελτιώνοντας έτσι τις εμπειρίες των χρηστών. Βελτιώνει την επικοινωνία και τη διαίσθηση της αλληλεπίδρασης ανθρώπου-μηχανής.
- Ενισχυμένη κατανόηση:
- Η κατανόηση του πλαισίου είναι μια μοναδική δεξιότητα για τα πολυτροπικά μοντέλα και είναι απαραίτητη για εργασίες όπως η σωστή ανταπόκριση και η κατανόηση του προφορικού λόγου. Συνδυάζουν την ανάλυση κειμένου και οπτικών δεδομένων για να το επιτύχουν αυτό.
- Αυτή η επίγνωση του πλαισίου είναι επίσης χρήσιμη για τα συστήματα που βασίζονται σε συνομιλίες. Χρησιμοποιώντας τόσο κείμενο όσο και οπτικές εισροές, τα πολυτροπικά μοντέλα μπορούν να παράγουν απαντήσεις με μια πιο ανθρώπινη αίσθηση.
- Ανθεκτικότητα: Μειώνουν την επιρροή του θορύβου ή των λαθών στις επιμέρους λειτουργίες και, ως εκ τούτου, είναι πιο ανθεκτικά στις αλλαγές και τις αβεβαιότητες των δεδομένων, δεδομένου ότι μπορούν να αντλούν από πολλαπλές πηγές πληροφοριών για να παράγουν προβλέψεις ή ταξινομήσεις.
- Όγκος δεδομένων: Χρειάζονται τεράστιοι όγκοι δεδομένων από πολλαπλές πηγές και τύπους για να είναι αποτελεσματική η εκπαίδευση και η μάθηση, αλλά η απόκτηση και η διαχείρισή τους μπορεί να είναι δύσκολη.
- Υπολογιστική πολυπλοκότητα: Συνήθως είναι υπολογιστικά απαιτητική η επεξεργασία και η ανάλυση δεδομένων από πολλούς τύπους ταυτόχρονα, γεγονός που απαιτεί ισχυρή υποδομή και αποτελεσματικούς αλγορίθμους.
- Συγχρονισμός δεδομένων: Η ευθυγράμμιση δεδομένων από διαφορετικές μορφές με έναν τρόπο μπορεί να αποτελέσει πρόκληση λόγω των διαφορών στη μορφοποίηση, το συγχρονισμό και τη σημασιολογία.
- Περιορισμένα σύνολα δεδομένων: Η απόδοση τους και η ικανότητά τους να γενικεύουν σε νέες εργασίες ή τομείς μπορεί να παρεμποδίστούν από την περιορισμένη διαθεσιμότητα επισημασμένων δεδομένων για εκπαίδευση.
- Ελλιπή δεδομένα: Ο χειρισμός ελλειπόντων δεδομένων σε διαφορετικές μορφές αναπαράστασης αποτελεί πρόκληση για τη διατήρηση της ακρίβειας και της ευρωστίας του μοντέλου.
- Πολυπλοκότητα λήψης αποφάσεων: Οι διαδικασίες λήψης αποφάσεων γίνονται πιο πολύπλοκες όταν ενσωματώνονται πληροφορίες από διάφορες λειτουργίες, γεγονός που καθιστά αναγκαία τη χρήση πολύπλοκων πλαισίων και αλγορίθμων για αποτελεσματική συλλογιστική και εξαγωγή συμπερασμάτων.
- AGI (Artificial General Intelligence): Η Τεχνητή Γενική Νοημοσύνη (ΤΓΝ) είναι ένας τύπος τεχνητής νοημοσύνης που ταιριάζει ή ξεπερνά τις ανθρώπινες ικανότητες σε ένα ευρύ φάσμα γνωστικών εργασιών. Σε αντίθεση με τη στενή τεχνητή νοημοσύνη, η οποία είναι σχεδιασμένη για συγκεκριμένες εργασίες, η ΤΓΝ είναι ευέλικτη, προσαρμοστική και έχει πλήρεις ικανότητες επίλυσης προβλημάτων. Θα μπορούσε θεωρητικά να αναπαράγει τις γνωστικές ικανότητες που μοιάζουν με τις ανθρώπινες, συμπεριλαμβανομένων της συλλογιστικής, της επίλυσης προβλημάτων, της αντίληψης, της μάθησης και της γλωσσικής κατανόησης.
Η AGI εξακολουθεί να είναι καθαρά θεωρητική σε αυτό το στάδιο. Οι περισσότεροι ερευνητές και ακαδημαϊκοί πιστεύουν ότι απέχουμε δεκαετίες από την υλοποίηση της ΤΓΝ – μερικοί μάλιστα προβλέπουν ότι δεν θα δούμε την ΤΓΝ αυτόν τον αιώνα (ή και ποτέ). Αν και οι τελευταίες τεχνολογίες Γενετικής ΤΝ, όπως η ChatGPT, ή DALL-E και άλλες έχουν γίνει πρωτοσέλιδα, είναι ουσιαστικά μηχανές πρόβλεψης – αν και πολύ καλές. Μπορούν να προβλέψουν, με μεγάλο βαθμό ακρίβειας, την απάντηση σε μια συγκεκριμένη ερώτηση, επειδή έχουν εκπαιδευτεί σε τεράστιες ποσότητες δεδομένων. Αυτό είναι εντυπωσιακό, αλλά δεν είναι σε ανθρώπινο επίπεδο απόδοσης όσον αφορά τη δημιουργικότητα, τη λογική σκέψη, την αισθητηριακή αντίληψη και άλλες ικανότητες.
Αντίθετα, τα εργαλεία ΤΓΝ θα μπορούσαν να διαθέτουν γνωστικές και συναισθηματικές ικανότητες (όπως η ενσυναίσθηση) που δεν διακρίνονται από αυτές ενός ανθρώπου. Ανάλογα με τον ορισμό που δίνετε στην ΤΓΝ, θα μπορούσαν ακόμη και να είναι ικανά να αντιλαμβάνονται συνειδητά το νόημα πίσω από αυτό που κάνουν. Το χρονοδιάγραμμα της εμφάνισης της ΑΓΙ είναι αβέβαιο. Αλλά όταν έρθει -και πιθανότατα θα έρθει κάποια στιγμή- θα είναι πολύ σημαντικό για κάθε πτυχή της ζωής μας, των επιχειρήσεων και των κοινωνιών μας.
Σε επόμενη δημοσίευση, θα αναλυθούν τα εργαλεία, οι τύποι των εφαρμογών, οι τεχνικές και υποδομές που (θα) επιτρέπουν την εξέλιξη των τεχνολογιών/εφαρμογών.
Ο Πάνος Κριτσώνης, μέλος του AICatalyst, βρίσκεται στο χώρο της πληροφορικής και του λογισμικού πάνω από 30 χρόνια, με έμφαση στο BFSI (Banking, Financial Services, and Insurance) και retail.
Τα τελευταία χρόνια, μεταξύ άλλων, το ενδιαφέρον του εστιάζεται στο Cloud, την Τεχνητή Νοημοσύνη, τις βέλτιστες τεχνικές ανάπτυξης λογισμικού/αρχιτεκτονικής και την αυτοματοποίηση/βελτιστοποίηση επιχειρηματικών διαδικασιών.Στην έρευνα αυτού του άρθρου βοήθησε το ChatGPT Enterprise.